
Kaggle Titanic

캐글 타이타닉 대회 참가하기
도입
- 데이터 사이언스 공부를 하면서 다양한 데이터에 대한 경험을 쌓는 것이 좋을 것 같아서 캐글 타이타닉 대회에 참가하려고 한다.
- 그동안 배운 머신러닝 가운데 나무기반 모델을 적용해보고 활용해 보는 것이 목적이다.
- 오늘 적용해볼 모델은 Decision Tree, Random Forest, XGBoost 이다.
Decision Tree
- 라이브러리 : sklearn.tree.DecisionTreeClassifier()
- 나무기반 모델의 기초가 되는 모델
Random Forest
- 라이브러리 : sklearn.ensemble.RandomForestClassifier()
- 앙상블기법 가운데 배깅의 대표 모델
XGBoost
- 라이브러리 : xgboost.XGBClassifier()
- 앙상블기법 가운데 부스팅의 대표 모델
데이터 준비
데이터 읽어오기
# 데이터를 불러온다
train = pd.read_csv( path_data + 'train.csv' )
test = pd.read_csv( path_data + 'test.csv' )
submission = pd.read_csv( path_data + 'gender_submission.csv' )
submission.set_index('PassengerId', inplace=True)
# 타겟과 특성을 지정한다
target = 'Survived' # Target Name
features = train.drop(columns=[target]).columns
rand_seed = 888
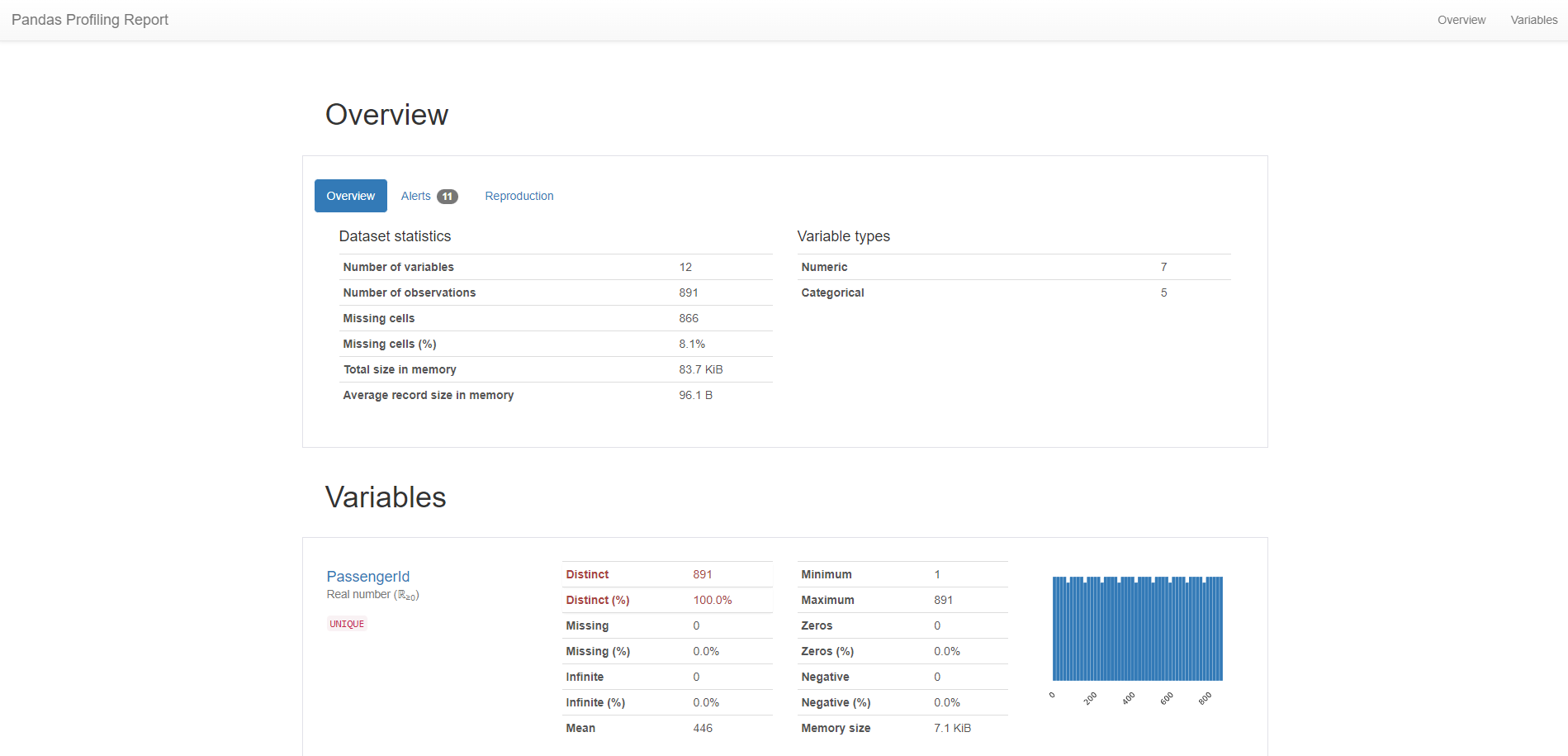
데이터 살펴보기
- pandas.ProfileReport() 함수를 이용하여 데이터 살펴보기
- 자세한 과정은 생략
특성공학
-특성공학 출처 : Kaggle에서 파이썬으로 데이터 분석 시작하기
| 기존 칼럼 | 신규 칼럼 | 설명 |
|---|---|---|
| Sex | Sex | 성별. female -> 0, male -> 1로 변환 |
| Embarked | Embarked | 탑승항. C -> 0, Q -> 1, S -> 2로 변환 |
| Name | Title | 이름에서 호칭을 추출. Master -> 0, Miss -> 1, Mr -> 2, Mrs -> 3, Other -> 4로 변환 |
| Age | AgeCategory | 나이를 qcut으로 8개의 구간으로 분리하여 카테고리화. 결측치는 호칭의 평균값으로 채움 |
| Cabin | CabinCategory | 방번호를 첫 글자만 따서 카테고리화. 결측치는 N으로 채움 |
| Fare | FareCategory | 운임을 8개의 구간으로 분리하여 카테고리화. 결측치는 0으로 채움 |
| SibSp, Parch | Family, IsAlone | 가족으로 합침. 혼자 탑승한 고객 정보 추출 |
| Ticket | TicketCategory | 티켓 번호의 첫 번째 번호만 추출하여 카테고리화 |
def feature_engineering(df):
""" 특성공학 함수 """
# Sex
df['Sex'] = df['Sex'].map({'female': 0, 'male': 1})
# Embarked
df.Embarked.fillna('S', inplace=True)
df['Embarked'] = df['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
# Title
df['Title'] = df.Name.str.extract(' ([A-Za-z]+)\.')
df['Title'] = df['Title'].replace(['Capt', 'Col', 'Countess', 'Don','Dona', 'Dr', 'Jonkheer', 'Lady','Major', 'Rev', 'Sir'], 'Other')
df['Title'] = df['Title'].replace('Mlle', 'Miss')
df['Title'] = df['Title'].replace('Mme', 'Mrs')
df['Title'] = df['Title'].replace('Ms', 'Miss')
df['Title'] = df['Title'].map({'Master': 0, 'Miss': 1, 'Mr': 2, 'Mrs':3, 'Other':4})
# Age
meanAge = df[['Title', 'Age']].groupby(['Title']).mean()
for index, row in meanAge.iterrows():
nullIndex = df[(df.Title == index) & (df.Age.isnull())].index
df.loc[nullIndex, 'Age'] = row[0]
df['AgeCategory'] = pd.qcut(df.Age, 8, labels=range(1, 9))
df.AgeCategory = df.AgeCategory.astype(int)
# Cabin
df.Cabin.fillna('N', inplace=True)
df['CabinCategory'] = df['Cabin'].str.slice(start=0, stop=1)
df['CabinCategory'] = df['CabinCategory'].map({ 'N': 0, 'C': 1, 'B': 2, 'D': 3, 'E': 4, 'A': 5, 'F': 6, 'G': 7, 'T': 8 })
# Fare
df.Fare.fillna(0, inplace=True)
df['FareCategory'] = pd.qcut(df.Fare, 8, labels=range(1, 9))
df.FareCategory = df.FareCategory.astype(int)
# SibSp, Parch
df['Family'] = df['SibSp'] + df['Parch'] + 1
df.loc[df["Family"] > 4, "Family"] = 5
df['IsAlone'] = 1
df.loc[df['Family'] > 1, 'IsAlone'] = 0
# Ticket
df['TicketCategory'] = df.Ticket.str.split()
df['TicketCategory'] = [i[-1][0] for i in df['TicketCategory']]
df['TicketCategory'] = df['TicketCategory'].replace(['8', '9', 'L'], '8')
df['TicketCategory'] = pd.factorize(df['TicketCategory'])[0] + 1
df.drop(['PassengerId', 'Ticket', 'Cabin', 'Fare', 'Name', 'Age', 'SibSp', 'Parch'], axis=1, inplace=True)
return df
train = feature_engineering(train)
test = feature_engineering(test)
탐색적 데이터 분석
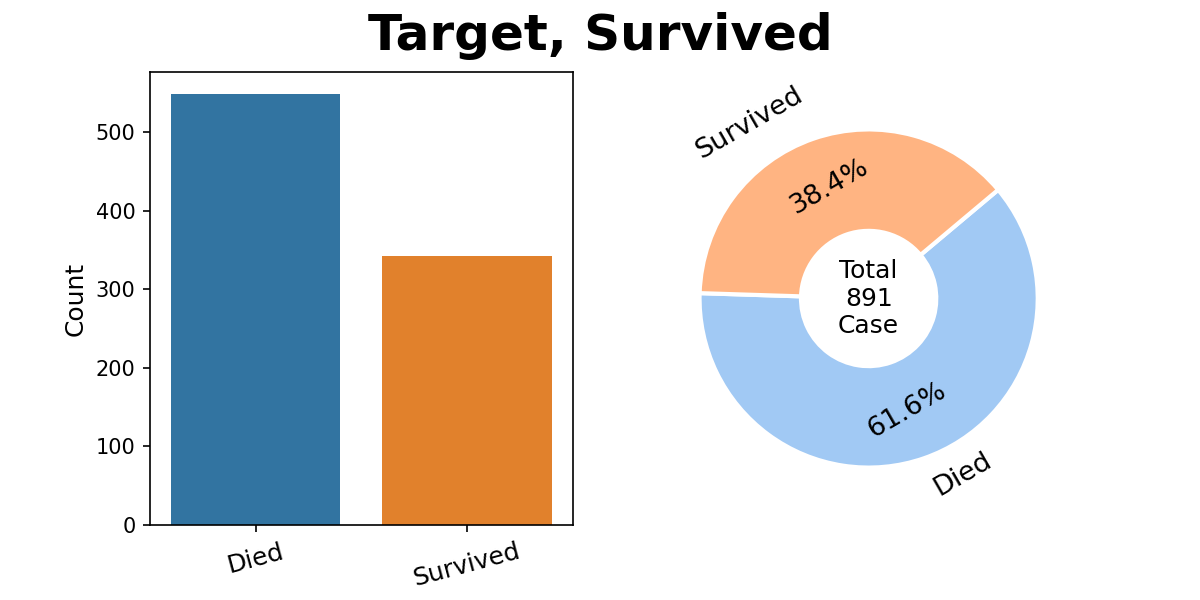
타겟의 분포
- 타겟이 약간 불균형한 것으로 보임
모델링
- 평가점수 계산을 위한 함수
def print_score(model, X_train, y_train, cv_n=3) :
""" 학습 된 모델에서 평가지표를 반환하는 함수 """
np.random.seed(rand_seed)
# 타겟 추정
y_train_pred = model.predict(X_train)
y_train_proba = model.predict_proba(X_train)[:, 1]
train_accuracy = accuracy_score (y_train, y_train_pred)
train_f1 = f1_score (y_train, y_train_pred)
train_roc_auc = roc_auc_score (y_train, y_train_proba)
val_accuracy_cv = cross_val_score(model, X_train, y_train, scoring='accuracy', cv=cv_n)
val_f1_cv = cross_val_score(model, X_train, y_train, scoring='f1', cv=cv_n)
val_roc_auc_cv = cross_val_score(model, X_train, y_train, scoring='roc_auc', cv=cv_n)
result_df = pd.DataFrame({'train' : [train_accuracy, train_f1, train_roc_auc],
'val_mean' : [val_accuracy_cv.mean(), val_f1_cv.mean(), val_roc_auc_cv.mean()],
'val_std' : [val_accuracy_cv.std(), val_f1_cv.std(), val_roc_auc_cv.std()],
}, index=['Accuracy','F1','AUC'])
# print(result_df.T)
return result_df.T
데이터 분할
- 정보누수를 방지하기 위하여 모델링 전에 데이터 분할
- 보통 8:2, 7:3으로 분할하지만 검증 데이터가 너무 적어서 6.5:3.5 로 분할
X_train, X_val = train_test_split(train, test_size=0.35, stratify=train[target], random_state=rand_seed)
y_train = X_train[target]
X_train = X_train[features]
y_val = X_val[target]
X_val = X_val[features]
X_test = test
기준 모델
- 내가 만드는 모델이 쓸만한 모델인지 확인하기 위하여 기준이 되는 모델을 선정
- 기준 모델은 최빈값 예측 모델
most_count = y_train.mode()[0] # 최빈값
y_base_pred = [most_count] * len(y_train) # 최빈값으로 예측값 생성
print(f'기준모델 정확도 : {accuracy_score(y_train, y_base_pred):.3f}')
# 기준모델 정확도 : 0.617
- 최빈값 기준모델이기 때문에 타겟의 최빈값인 0으로 모든 예측값을 만든 모델
- 기준모델의 정확도(Accuracy)는 타겟의 최빈값 0의 비율과 같은 0.617
기본값 모델
- 라이브러리의 기본값들로 만든 모델
# 모델 학습
model_init = ['dt', 'rf', 'xg']
model_name = ['DecisionTreeClassifier', 'RandomForestClassifier', 'XGBClassifier']
dt_model1, rf_model1, xg_model1 = [0,0,0]
dt_score1_train, dt_score1_val, rf_score1_train, rf_score1_val, xg_score1_train, xg_score1_val = [0,0,0,0,0,0]
for i, model in enumerate(model_init):
globals()[f'{model}_model1'] = globals()[f'{model_name[i]}'](random_state = rand_seed)
globals()[f'{model}_model1'].fit(X_train, y_train);
# 평가 점수 계산
for i, model in enumerate(model_init):
globals()[f'{model}_score1_train'] = classification_report(y_train, globals()[f'{model}_model1'].predict(X_train), output_dict=True)
globals()[f'{model}_score1_val'] = classification_report(y_val, globals()[f'{model}_model1'].predict(X_val), output_dict=True);
# Results Table
results_df = pd.DataFrame(index=['Train Accuracy','Val Accuracy','Train F1','Val F1'])
results_df['Decision Tree'] = [dt_score1_train["accuracy"], dt_score1_val["accuracy"], dt_score1_train["1"]["f1-score"], dt_score1_val["1"]["f1-score"]]
results_df['Random Forest'] = [rf_score1_train["accuracy"], rf_score1_val["accuracy"], rf_score1_train["1"]["f1-score"], rf_score1_val["1"]["f1-score"]]
results_df['XGBoost'] = [xg_score1_train["accuracy"], xg_score1_val["accuracy"], xg_score1_train["1"]["f1-score"], xg_score1_val["1"]["f1-score"]]
results_df.style.background_gradient(axis='columns',cmap='coolwarm').format(thousands=',', precision=4)
| Decision Tree | Random Forest | XGBoost | |
|---|---|---|---|
| Train Accuracy | 0.968912 | 0.968912 | 0.956822 |
| Val Accuracy | 0.782051 | 0.801282 | 0.788462 |
| Train F1 | 0.957746 | 0.958333 | 0.942529 |
| Val F1 | 0.696429 | 0.725664 | 0.713043 |
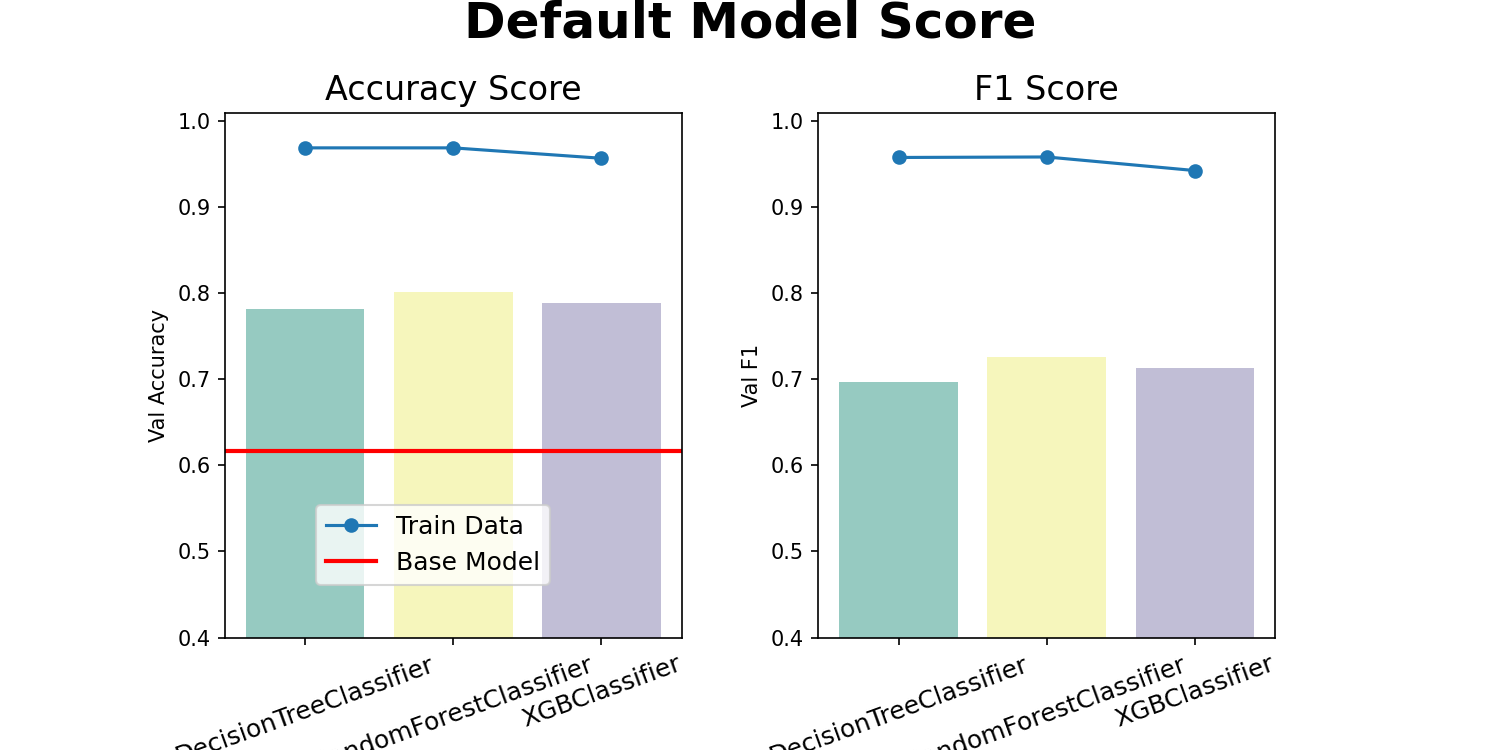
- 라이브러리에서 기본값들을 미리 잘 설정해놔서 그런지 기본값만으로도 점수가 잘 나온다.
- 하지만 Train와 Validation의 차이가 커서 과적합이 발생한 상황이다.
러닝 커브
- 나무기반 모델에서 성능에 가장 영향이 큰 하이퍼파라미터
max_depth의 러닝커브를 살펴보자
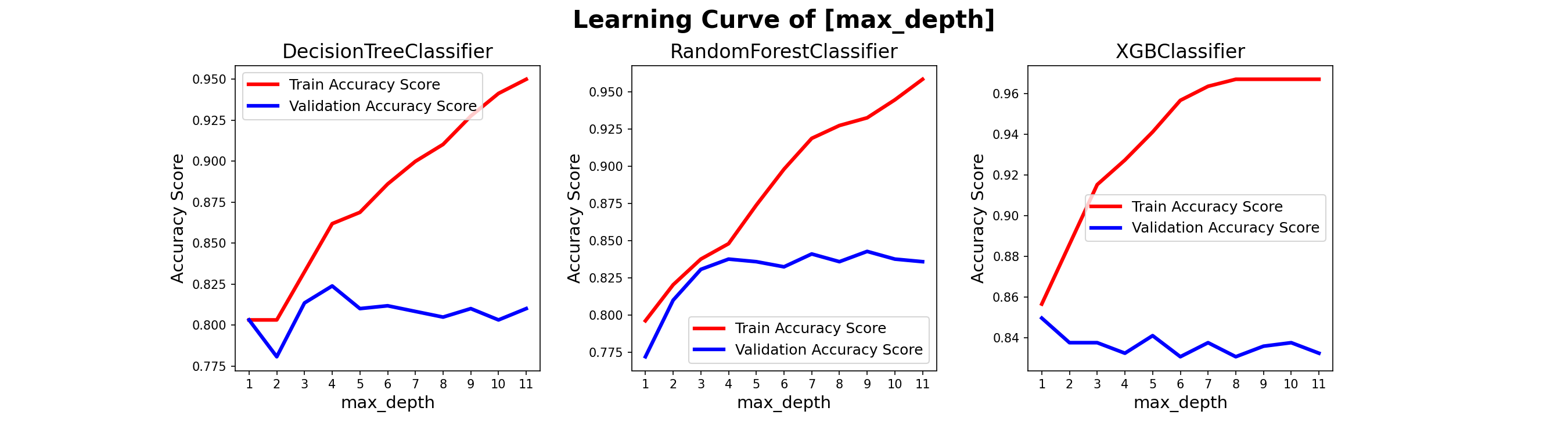
- Decision Tree와 Random Forest는 4정도에 최적화가 이루어지고, XGBoost는 잘 모르겠다.
GridSearchCV
- sklearn.model_selection.GridSearchCV()을 이용하여 최적의 하이퍼파라미터를 찾았다.
- GridSearchCV 는 모든 조합을 학습하기 때문에 시간이 오래걸리는 단점이 있다.
- 그래서 영향이 클 것으로 예상되는 몇개의 하이퍼파라미터를 투입하였다.
하이퍼파라미터 튜닝 : Decision Tree
%%time
# Decision Tree
dt_classifier = DecisionTreeClassifier()
dt_params = {
'criterion' : ['gini', 'entropy'],
'max_depth' : [5, 6, 7],
'min_samples_split' : [2, 4, 8, 16],
'min_samples_leaf' : [1, 2, 4, 8]
}
dt_gridCV = GridSearchCV(dt_classifier, param_grid = dt_params, cv = 3, scoring = "accuracy", verbose = 1)
dt_gridCV.fit(X_train, y_train)
print(f'✅ Best Params : {dt_gridCV.best_params_}')
print(f'✅ Best Score : {dt_gridCV.best_score_}')
# Fitting 3 folds for each of 96 candidates, totalling 288 fits
# ✅ Best Params : {'criterion': 'entropy', 'max_depth': 6, 'min_samples_leaf': 4, 'min_samples_split': 4}
# ✅ Best Score : 0.8359240069084629
# CPU times: user 1.17 s, sys: 9.7 ms, total: 1.17 s
# Wall time: 1.18 s
- 파라미터 2 X 3 X 4 X 4 = 96 번, CV 3번, 총 288번(96 X 3)의 학습이 이루어졌다.
하이퍼파라미터 튜닝 : Random Forest
%%time
# Random Forest
rf_classifier = RandomForestClassifier()
rf_params = {
'n_estimators' : range(60, 150, 10),
'max_depth' : range(3, 14, 1),
}
rf_gridCV = GridSearchCV(rf_classifier, param_grid = rf_params, cv = 3, scoring = "accuracy", verbose = 1)
rf_gridCV.fit(X_train, y_train)
print(f'✅ Best Params : {rf_gridCV.best_params_}')
print(f'✅ Best Score : {rf_gridCV.best_score_}')
# Fitting 3 folds for each of 99 candidates, totalling 297 fits
# ✅ Best Params : {'max_depth': 8, 'n_estimators': 130}
# ✅ Best Score : 0.8462867012089811
# CPU times: user 50.4 s, sys: 316 ms, total: 50.7 s
# Wall time: 51.1 s
- 파라미터 9 X 11 = 99 번, CV 3번, 총 297번(99 X 3)의 학습이 이루어졌다.
하이퍼파라미터 튜닝 : XGBoost
%%time
# XGBoost
xg_classifier = XGBClassifier()
xg_params = {
'n_estimators' : range(60, 131, 10),
'max_depth' : range(6, 13, 1),
'learning_rate' : [0.01, 0.1, 0.3]
}
xg_gridCV = GridSearchCV(xg_classifier, param_grid = xg_params, cv = 3, scoring = "accuracy", verbose = 1)
xg_gridCV.fit(X_train, y_train)
print(f'✅ Best Params : {xg_gridCV.best_params_}')
print(f'✅ Best Score : {xg_gridCV.best_score_}')
# Fitting 3 folds for each of 168 candidates, totalling 504 fits
# ✅ Best Params : {'learning_rate': 0.1, 'max_depth': 11, 'n_estimators': 100}
# ✅ Best Score : 0.85146804835924
# CPU times: user 1min 18s, sys: 4.59 s, total: 1min 22s
# Wall time: 49.4 s
- 파라미터 8 X 8 X 3 = 168 번, CV 3번, 총 504번(168 X 3)의 학습이 이루어졌다.
모델 해석
트리 그래프
- Decision Tree 의 트리 그래프를 그리면 어떠한 경우에 생존, 사망인지 시각적으로 확인할 수 있다.
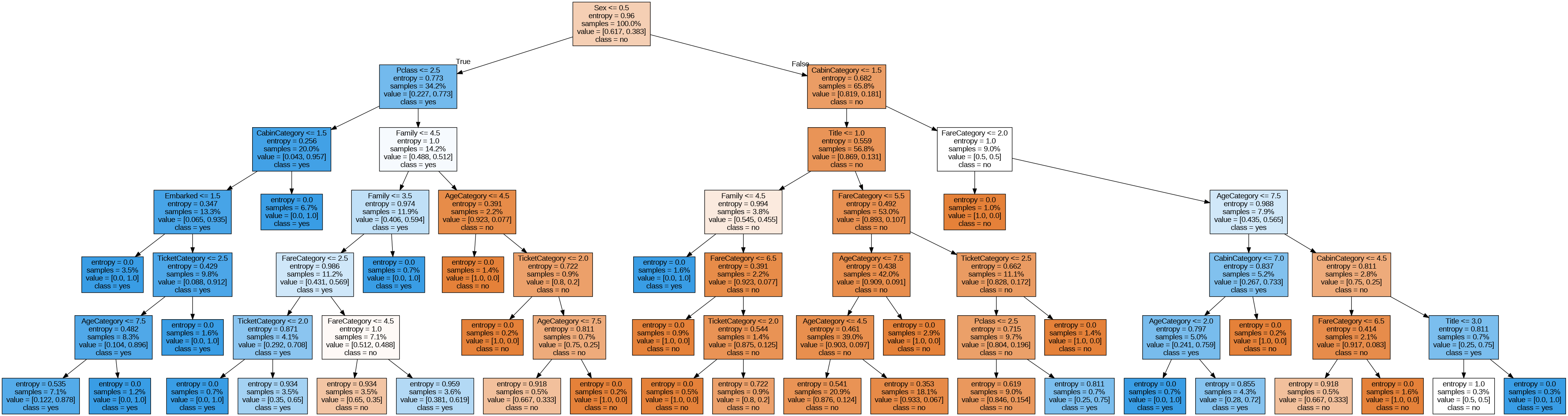
- XGBoost 라이브러리도 트리 그래프를 그릴 수 있다.
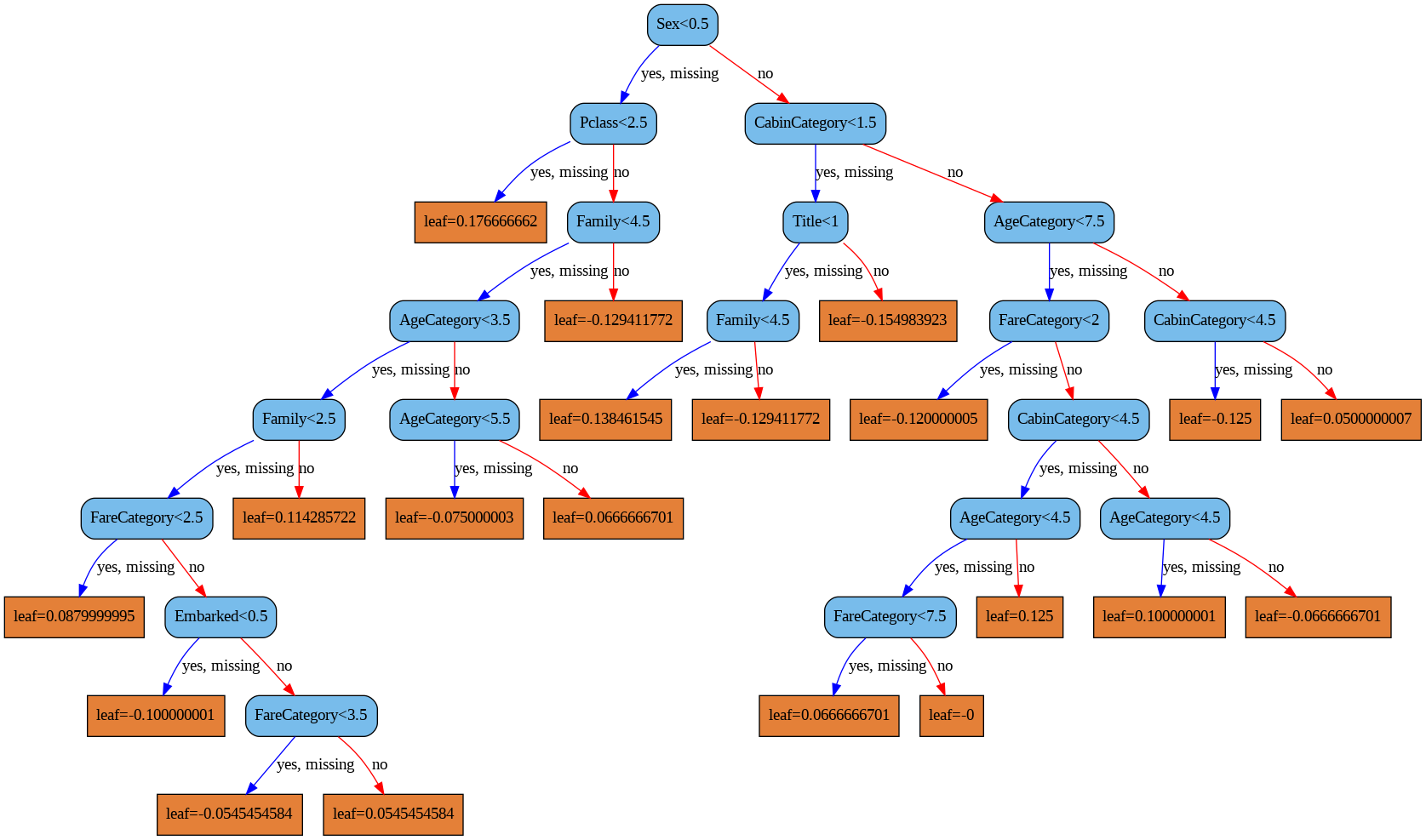
- 1~2 분기까지는 두 모델이 같지만 그 후로는 조금씩 다르다.
특성 중요도
- Decision Tree의 특성중요도를 보면 MDI(Mean Decrease Impurity) 방식은 Sex - Pclass - CabinCategory 순서로 특성이 중요하지만, PI(Permutation Importance) 방식은 Sex - Title - Pclass 순서로 특성이 중요하다.
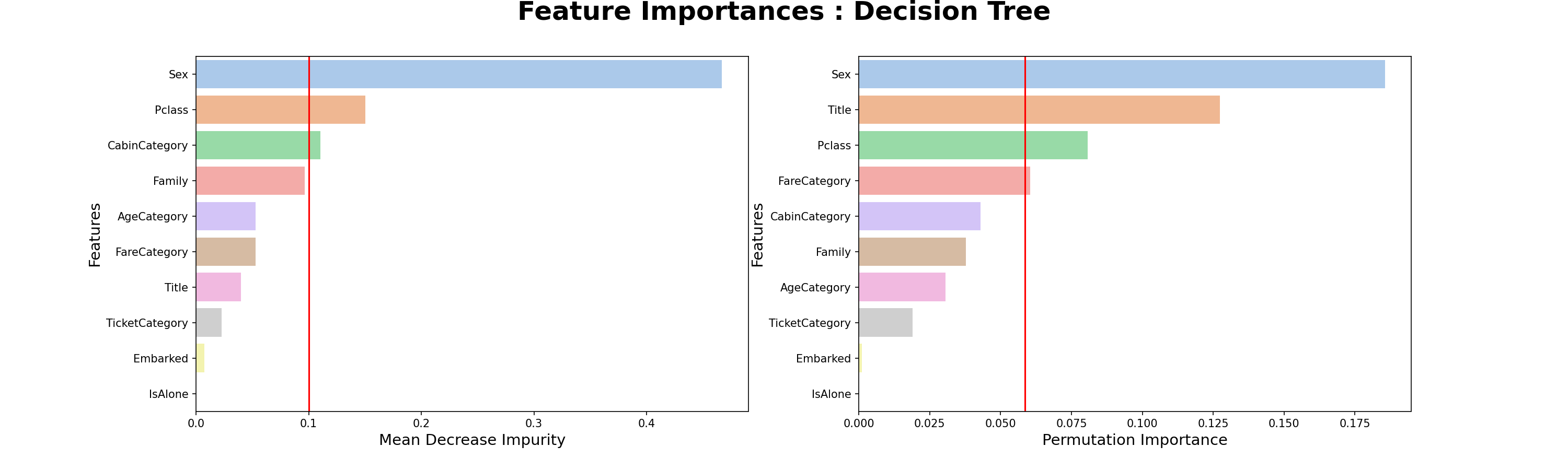
- Randome Forest의 특성중요도에서 MDI방식은 Decision Tree와 같지만, PI방식은 조금 차이가 있다.
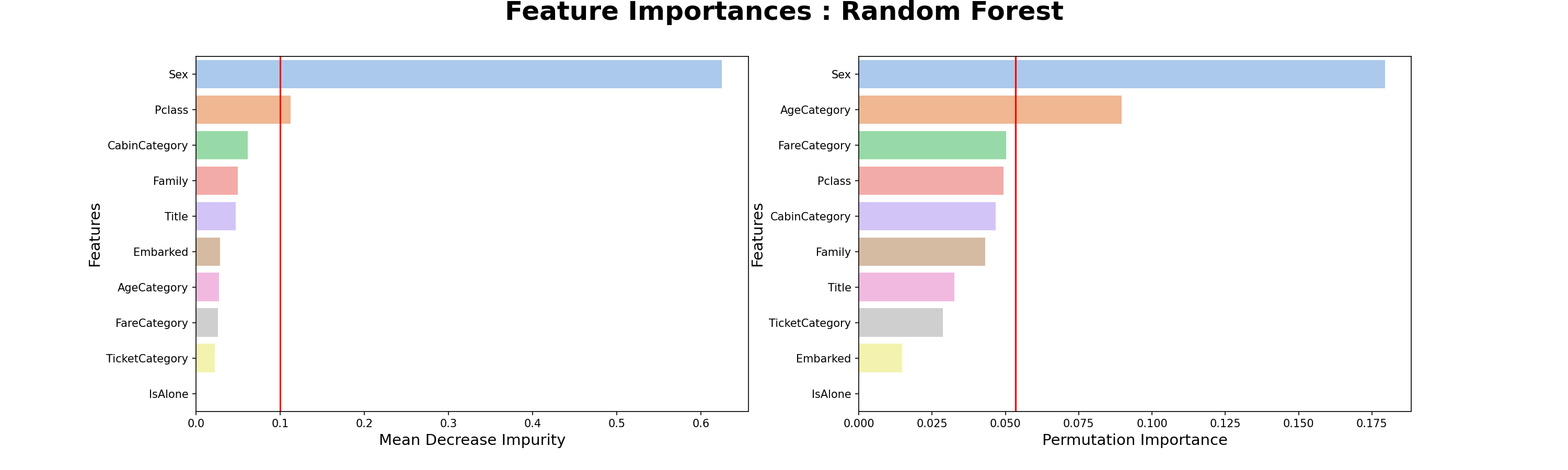
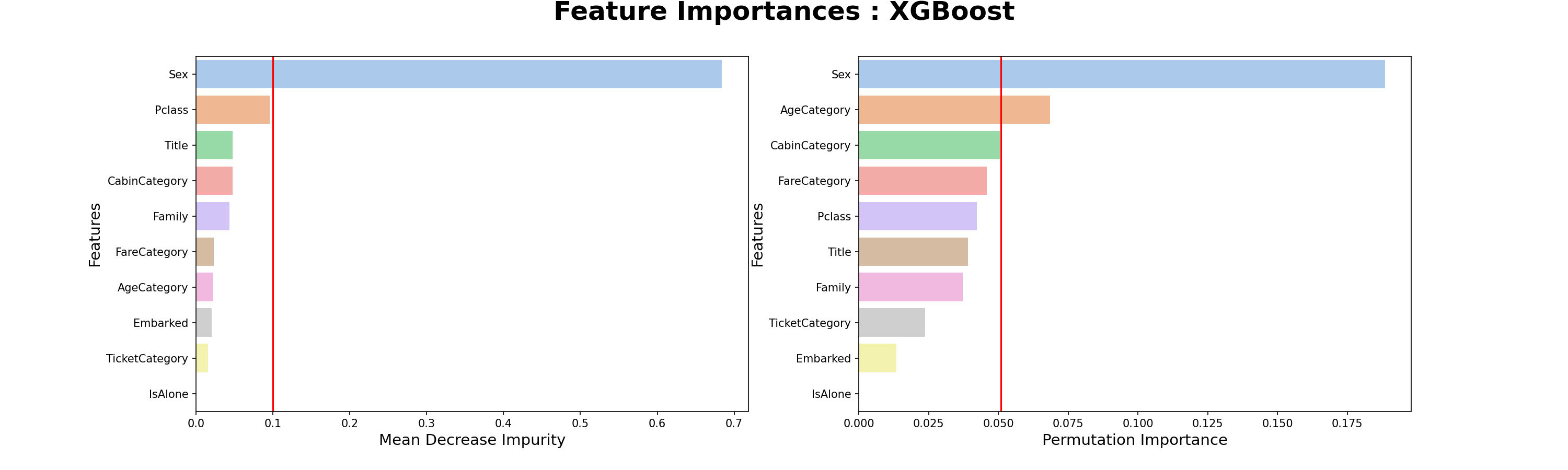
- 모델에 따라서 특성 중요도가 다르고, 특성중요도 계산 방식에 따라서도 다르다.
캐글 제출
- 세 모델 모두 타겟을 추정하여 캐글에 제출하였다.

최종 점수
- Decision Tree = 0.75837
- Random Forest = 0.77272
- XGBoost = 0.78708
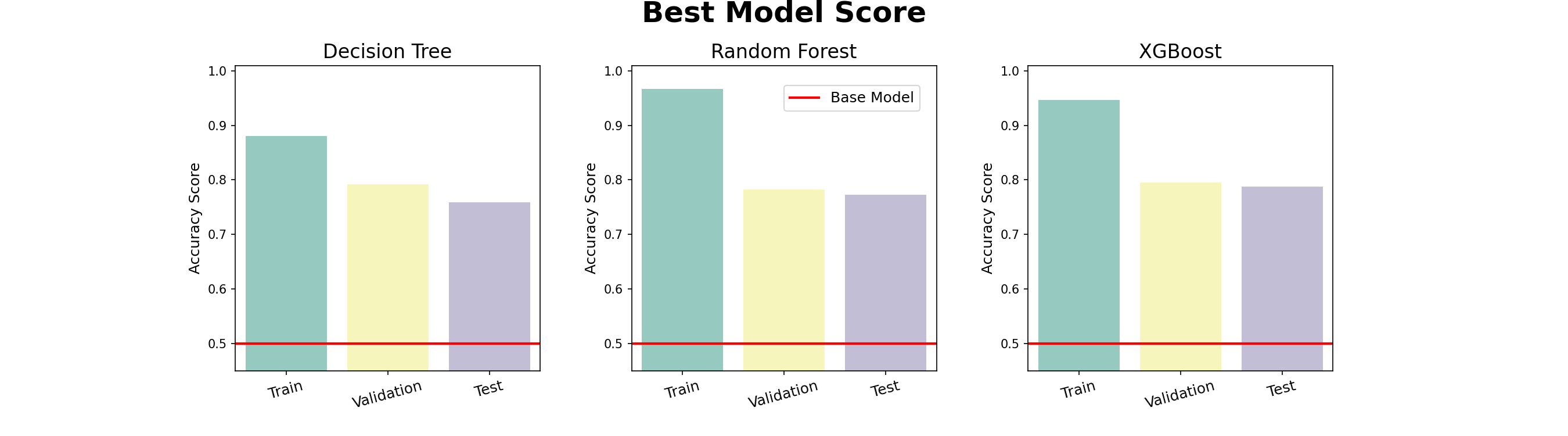
- Random Forest와 XGBoost는 아직 과적합이 많이 남아있는 모습이다.
- 베이지안서치 등으로 하이퍼파라미터 튜닝을 더 시도해 보면 점수를 올릴 수 있을 것 같다.
끝까지 읽어주셔서 감사합니다😉


댓글남기기